LR parsers are used to parse the large class of context free grammars. This technique is called LR(k) parsing.
• L is left-to-right scanning of the input.
• R is for constructing a right most derivation in reverse.
• k is the number of input symbols of lookahead that are used in making parsing decisions.
There are three widely used algorithms available for constructing an LR parser:
• SLR(l) – Simple LR
o Works on smallest class of grammar.
o Few number of states, hence very small table.
o Simple and fast construction.
• LR( 1) – LR parser
o Also called as Canonical LR parser.
o Works on complete set of LR(l) Grammar.
o Generates large table and large number of states.
o Slow construction.
• LALR(l) – Look ahead LR parser
o Works on intermediate size of grammar.
o Number of states are same as in SLR(l).
Reasons for attractiveness of LR parser
• LR parsers can handle a large class of context-free grammars.
• The LR parsing method is a most general non-back tracking shift-reduce parsing method.
• An LR parser can detect the syntax errors as soon as they can occur.
• LR grammars can describe more languages than LL grammars.
Drawbacks of LR parsers
• It is too much work to construct LR parser by hand. It needs an automated parser generator.
• If the grammar contains ambiguities or other constructs then it is difficult to parse in a left-to-right scan of the input.
We’ll be covering the following topics in this tutorial:
Model of LR Parser
LR parser consists of an input, an output, a stack, a driver program and a parsing table that has two functions
1. Action
2. Goto
The driver program is same for all LR parsers. Only the parsing table changes from one parser to another.
The parsing program reads character from an input buffer one at a time, where a shift reduces parser would shift a symbol; an LR parser shifts a state. Each state summarizes the information contained in the stack.
The stack holds a sequence of states, so, s1, · ·· , Sm, where Sm is on the top.

Action This function takes as arguments a state i and a terminal a (or $, the input end marker). The value of ACTION [i, a] can have one of the four forms:
i) Shift j, where j is a state.
ii) Reduce by a grammar production A—> β.
iii) Accept.
iv) Error.
Goto This function takes a state and grammar symbol as arguments and produces a state.
If GOTO [Ii ,A] = Ij, the GOTO also maps a state i and non terminal A to state j.
Behavior of the LR parser
1. If ACTION[sm, ai] = shift s. The parser executes the shift move, it shifts the next state s onto the stack, entering the configuration
a) Sm – the state on top of the stack.
b) ai– the current input symbol.
2. If ACTION[sm, ai] =reduce A—> β, then the parser executes a reduce move, entering the configuration
(s0s1 … S(m-r)S, ai+l … an$)
a) where r is the length of β and s= GOTO[sm – r, A].
b) First popped r state symbols off the stack, exposing state Sm-r·
c) Then pushed s, the entry for GOTO[sm-r, A], onto the stack.
3. If ACTION[sm, ai] = accept, parsing is completed.
4. If ACTION[sm, ai] = error, the parser has discovered an error and calls an error recovery routine.
LR Parsing Algorithm
Algorithm LR Parsing Algorithm.
Input Input string w,
LR-Parsing table with functions ACTION and
GOTO for a grammar G
Output If w is in L(G), the reduction steps of a
bottom-up parse for w,
otherwise, an error indication.
Method Initially, the parser has So on its stack,
where So is the initial state, and w $ in the
input buffer.
let a be the first symbol of w $
while(l) { //repeat forever
let s be the state on top of the stack;
if(ACTION[s, a] =shift t {
push t onto the stack;
let a be the next input symbol;
} else if (ACTION [s, a] = reduce A—> β) {
pop β symbols off the stack;
let state t now be on top of the stack;
push GOTO[t, A] onto the stack;
output the production A—> β;
} else if (ACTION [s, a] accept) break;
//parsing is done
else call error-recovery routine;
}
LR(O) Items
An LR(O) item of a grammar G is a production of G with a dot at some position of the body.
(eg.)
A —> •XYZ
A —> XeYZ
A —> XYeZ
A —> XYZ•
One collection of set of LR(O) items, called the canonical LR(O) collection, provides finite automaton that is used to make parsing decisions. Such an automaton is called an LR(O) automaton.
LR(O) Parser I SLR(1) Parser
An LR(O)parser is a shift-reduce parser that uses zero tokens of lookahead to determine what action to take (hence the 0). This means that in any configuration of the parser, the parser must have an unambiguous action to choose-either it shifts a specific symbol or applies a specific reduction. If there are ever two or more choices to make, the parser fails and the grammar is not LR(O).
An LR parser makes shift-reduce decisions by maintaining states to keep track of parsing. States represent a set of items.
Closure of item sets
If I is a set of items for a grammar G, then CLOSURE(I) is the set of items constructed from I by the two rules.
• Initially, add every item I to CLOSURE(I).
• If A —> αB,β is in CLOSURE(I) and B —> ɣ is a production, then add the item B —> • ɣ to CLOSURE(i), if it is not already there. Apply this rule until no more items can be added to CLOSURE (!).
Construct canonical LR(O) collection
• Augmented grammar is defined with two functions, CLOSURE and GOTO. If G is a grammar with start symbol S, then augmented grammar G’ is G with a new start symbol S’ —> S.
• The role of augmented production is to stop parsing and notify the acceptance of the input i.e., acceptance occurs when and only when the parser performs reduction by S’ —> S.
Limitations of the LR(O) parsing method
Consider grammar for matched parentheses
1. S’ —> S
2. S’ —> (S) S
3. S’ —> Ɛ
The LR(O) DFA of grammar G is shown below
In states: 0, 2 and 4 parser can shift (and reduce Ɛ to S)
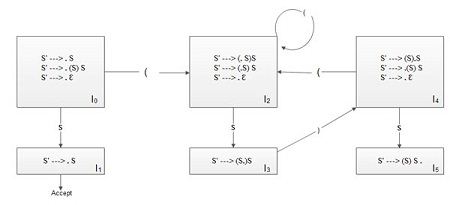
Conflicts
Conflicts are the situations which arise due to more than one option to opt for a particular step of shift or reduce.
• Two kinds of conflicts may arise.
Shift-reduce and reduce-reduce.
• In state 0 parser encounters a conflict.
It can shift state 2 on stack when next token is (.
It can reduce production 2: S —> Ɛ on +.
This is a called a shift-reduce conflict.
This conflict also appears in states 2 and 4.

Shift-reduce conflict parser can shift and can reduce.
Reduce-reduce conflict two (or more) productions can be reduced.
SLR(1) grammars
• SLR(l) parsing increases the power of LR(O) significantly.
Look ahead token is used to make parsing decisions
Reduce action is applied more selectively according to FOLLOW set.
• A grammar is SLR(l) if two conditions are met in every state.
If A —> α • x ɣ and B —> β ,•then token x Ɛ FOLLOW(B).
If A —> α • and B —> • then FOLLOW(A) П FOLLOW(B) = Ø.
• Violation of first condition results in shift-reduce conflict.
A—> α • x ɣ and B —> β• and x Ɛ FOLLOW(B) then …
Parser can shift x and reduce B —> β.
• Violation of second condition results in reduce-reduce conflict.
A—> α • and B —> β,•and x Ɛ FOLLOW(A) n FOLLOW(B).
Parser can reduce A —> α and B —> β,.
• SLR(l) grammars are a superset of LR(O) grammars.
LR(1) Parser I Canonical LR (CLR)
• Even more powerful than SLR(l) is the LR(l) parsing method.
• LR(l) includes LR(O) items and a look ahead token in itemsets.
• An LR(l) item consists of,
o Grammar production rule.
o Right-hand position represented by the dot and.
o Lookahead token.
o A —>X1 · · · Xi • Xi+1 · · · Xn, l where l is a lookahead token
• The • represents how much of the right-hand side has been seen,
o X1 · · · Xi appear on top of the stack.
o Xi+l · · · Xn are expected to appear on input buffer.
• The lookahead token l is expected after X1 · · · Xn appears on stack.
• An LR(l) state is a set of LR(l) items.
Introduction to LALR Parser
• LALR stands for lookahead LR parser.
• This is the extension of LR(O) items, by introducing the one symbol of lookahead on the input.
• It supports large class of grammars.
• The number of states is LALR parser is lesser than that of LR( 1) parser. Hence, LALR is preferable as it can be used with reduced memory.
• Most syntactic constructs of programming language can be stated conveniently.
Steps to construct LALR parsing table
• Generate LR(l) items.
• Find the items that have same set of first components (core) and merge these sets into one.
• Merge the goto’s of combined itemsets.
• Revise the parsing table of LR(l) parser by replacing states and goto’s with combined states and combined goto’s respectively.
 Dinesh Thakur holds an B.C.A, MCDBA, MCSD certifications. Dinesh authors the hugely popular
Dinesh Thakur holds an B.C.A, MCDBA, MCSD certifications. Dinesh authors the hugely popular