Syntax directed definition specifies the values of attributes by associating semantic rules with the grammar productions.
It is a context free grammar with attributes and rules together which are associated with grammar symbols and productions respectively.
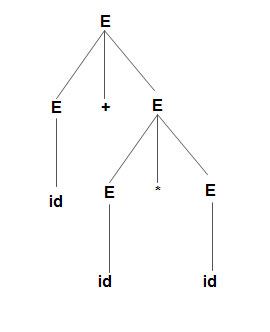
The process of syntax directed translation is two-fold:
• Construction of syntax tree and
• Computing values of attributes at each node by visiting the nodes of syntax tree.
Semantic actions
Semantic actions are fragments of code which are embedded within production bodies by syntax directed translation.
They are usually enclosed within curly braces ({ }).
It can occur anywhere in a production but usually at the end of production.
(eg.)
E—> E1 + T {print ‘+’}
Types of translation
• L-attributed translation
o It performs translation during parsing itself.
o No need of explicit tree construction.
o L represents ‘left to right’.
• S-attributed translation
o It is performed in connection with bottom up parsing.
o ‘S’ represents synthesized.
Types of attributes
• Inherited attributes
o It is defined by the semantic rule associated with the production at the parent of node.
o Attributes values are confined to the parent of node, its siblings and by itself.
o The non-terminal concerned must be in the body of the production.
• Synthesized attributes
o It is defined by the semantic rule associated with the production at the node.
o Attributes values are confined to the children of node and by itself.
o The non terminal concerned must be in the head of production.
o Terminals have synthesized attributes which are the lexical values (denoted by lexval) generated by the lexical analyzer.
Syntax directed definition of simple desk calculator
Production | Semantic rules |
L —> En | L.val = E.val |
E —> E1+ T | E.val = E1.val+ T.val |
E —> T | E.val = T.val |
T—> T1*F | T.val = Ti.val x F.val |
T —> F | T.val = F.val |
F —> (E) | F.val = E.val |
F —> digit | F.val = digit.lexval |
Syntax-directed definition-inherited attributes
Production | Semantic Rules |
D —>TL | L.inh = T.type |
T —> int | T.type =integer |
T —> float | T.type = float |
L —> L1, id | L1.inh = L.inh addType (id.entry, Linh) |
L —> id | addType (id.entry, L.inh) |
• Symbol T is associated with a synthesized attribute type.
• Symbol L is associated with an inherited attribute inh,
Types of Syntax Directed Definitions
S-attributed Definitions
Syntax directed definition that involves only synthesized attributes is called S-attributed. Attribute values for the non-terminal at the head is computed from the attribute values of the symbols at the body of the production.
The attributes of a S-attributed SDD can be evaluated in bottom up order of nodes of the parse tree. i.e., by performing post order traversal of the parse tree and evaluating the attributes at a node when the traversal leaves that node for the last time.
Production | Semantic rules |
L —> En | L.val = E.val |
E —> E1+ T | E.val = E1.val+ T.val |
E —> T | E.val = T.val |
T—> T1*F | T.val = Ti.val x F.val |
T —> F | T.val = F.val |
F —> (E) | F.val = E.val |
F —> digit | F.val = digit.lexval |
L-attributed Definitions
The syntax directed definition in which the edges of dependency graph for the attributes in production body, can go from left to right and not from right to left is called L-attributed definitions. Attributes of L-attributed definitions may either be synthesized or inherited.
If the attributes are inherited, it must be computed from:
• Inherited attribute associated with the production head.
• Either by inherited or synthesized attribute associated with the production located to the left of the attribute which is being computed.
• Either by inherited or synthesized attribute associated with the attribute under consideration in such a way that no cycles can be formed by it in dependency graph.
Production | Semantic Rules |
T —> FT’ | T ‘.inh = F.val |
T ‘ —> *FT1’ | T’1.inh =T’.inh x F.val |
In production 1, the inherited attribute T’ is computed from the value of F which is to its left. In production 2, the inherited attributed Tl’ is computed from T’. inh associated with its head and the value of F which appears to its left in the production. i.e., for computing inherited attribute it must either use from the above or from the left information of SDD.







")


")
















