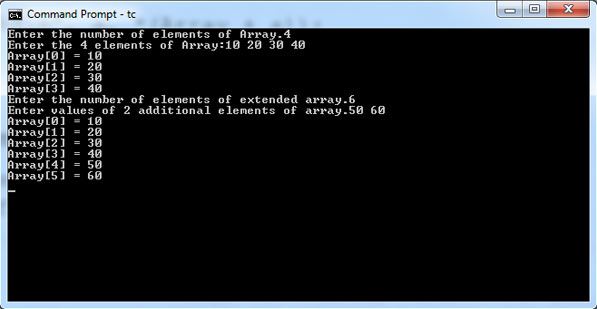
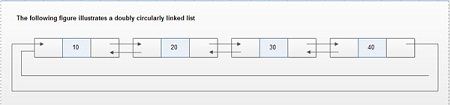
In a doubly-circularly-linked list, each node has two links, similar to a doubly-linked list, except that the previous link of the first node points to the last node and the next link of the last node points to the first node. As in doubly-linked lists, insertions and removals can be done at any point with access to any nearby node.
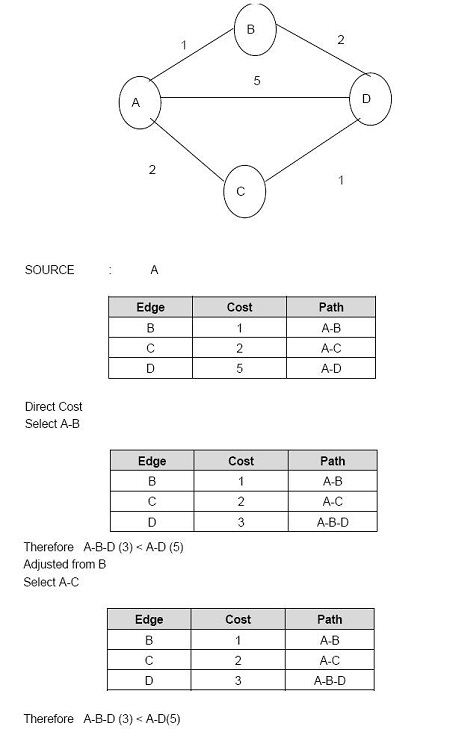

 Function")