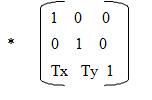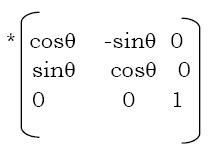The process by which CONTINUOUS TONE photographs are reproduced in print (for example in newspapers and magazines) by reducing them to a grid of tiny dots. (The resulting image is also commonly known as a halftone.) Each individual dot is printed using a single coloured ink of fixed intensity, and the intensity of colour the reader perceives is controlled by varying the size and density of the dots to reveal more or less of the underlying white paper.
The superficial similarity between this use of dots in printing and the PIXELS that constitute computer images is misleading, since pixels actually vary in colour and intensity rather than size. When computer-generated pictures are prepared for printing, each pixel gets broken up into a sub-grid of halftone dots that simulate its tonal value spatially. The pixel and halftone grids may interfere with each other and cause the problem called SCREEN CLASH.