Definition: A Scheduling Algorithm is the algorithm which tells us how much CPU time we can allocate to the processes.
These scheduling algorithms are either preemptive or non-preemptive.
Preemptive Scheduling Algorithms are those which are based on the priority of the processes. By preference, when a high priority process enters, it preempts a low priority process in between and executes the high priority process first.
Non-preemptive Scheduling Algorithms are those who can’t be preempted in between, i.e. we can not take control of CPU in between until the current process completes its execution.
We’ll be covering the following topics in this tutorial:
Purpose or Objectives of a Scheduling Algorithm
The goals of scheduling algorithms are as follows:
• Maximum utilization of CPU so that we can keep the CPU as busy as possible.
• Throughput means the number of processes which are completing their execution in per unit time. There must be maximum throughput.
• Turnaround time means that the time taken by the processes to finish their implementation. It must be a minimum.
• Waiting time is that time for which the process remains in the ready queue. It must be a minimum.
• There must be fare allocation of CPU.
• Response time is the time when the process gives its first response. It must be a minimum.
Why do we need scheduling?
As we know, a process needs CPU time and I/O time both for its execution. In a multi-programming system, one process can use CPU while another process is waiting for I/O whereas, on the other hand in a uni programming system, all the time get wasted in waiting for I/O whereas CPU is free during that time.
Types of Scheduling Algorithms
There are eight different types of scheduling algorithms whose name are as follows:
To understand these scheduling, first, we discuss some terms that we need in each scheduling process.
• Arrival time is the time at which the process arrives in the ready queue for execution, and it is given in our table when we need to calculate the average waiting time.
• Completion time is the time at which the process finishes its execution.
• Turnaround time is the difference between completion time and arrival time, i.e. turnaround time = Completion time- arrival time
• Burst time is the time required by the process for execution of the process by CPU.
• Waiting time (W.T) is the difference between turnaround time and burst time, i.e. waiting time= Turnaround time – Burst time
Now we will discuss the scheduling algorithms one by one.
First Come First Serve(FCFS) Scheduling
We can abbreviate First Come First Scheduling as FCFS scheduling. In this scheduling, the process which arrives first in front of CPU will be executed first by the CPU. It is a non-preemptive type of scheduling algorithm, i.e. in this scheduling algorithm priority of processes does not matter, or you can say that whatever the priority of the process is, the process will be executed in the manner they arrived in front of the CPU.
FCFS scheduling is also called as FIFO, i.e. first in first out. We can also write C/C++ program for first come first serve scheduling algorithm.
Example: if we consider the real-life example of FCFS scheduling, it will be taken as buying the ticket on the ticket counter. As we know while purchasing the ticket, every passenger is served in the queue manner. Similarly, happen in the FCFS scheduling. Thus, the process which arrives first in a queue will first be served by the CPU and the other process will later on served by CPU.
Calculating Average Waiting Time for Scheduling
For seeing the performance, we will calculate the average waiting time of the processes. We will explain this with the help of an example.
Example: consider the three processes P1, P2 and P3 whose arrival time and burst time are adequately illustrated in the table given below. The arrival of the processes for execution is in the same manner as they are shown in the table.
| Process | Burst time | Arrival |
| P1 | 21 | 1st |
| P2 | 3 | 2nd |
| P3 | 5 | 3rd |
![]() This is the GANTT chart of the above process
This is the GANTT chart of the above process
The average waiting time or AWT= (0+21+24)/3= 15ms
Firstly the process P1 will be executed by the CPU as its arrival time is 0.
• So, there is no waiting time for the process P1 as CPU sits idle during this time.
• The burst time of the process P1 is 21ms. So, it will take 21 ms to complete its execution. Thus, this time will be counted as waiting time for process P2.
• In the same way, the waiting time for the process P3 can be calculated when we add the execution time of both the processes P1 and P2 i.e. waiting time for the process P3= 21+3=24 ms
• Following the same procedure, the waiting time for the process P4= execution time of P1+P2+P3= 21+3+5= 29ms
So, we can completely explained this process through the GANTT chart which is illustrated above.
Advantages of First Come First Serve scheduling
• It is easy to implement.
• It is easy to understand.
Disadvantages of First Come First Serve scheduling
• In FCFS scheduling, the priority of the processes for executing by the CPU does not matter as it is a non-preemptive scheduling process.
Example : if a process which has less priority can be executed first by the CPU and it can take more time as per its requirement. Suppose if suddenly a process which has the high priority reaches in front of CPU for execution, then the CPU does not execute this high priority process. So, this high priority process has to wait because of non-preemptive scheduling approach of CPU.
• In this, average waiting time or AWT is high i.e. average waiting time is not optimal.
• In FCFS, there is no possibility of parallel utilization of resources, which give result to Convoy Effect or you can say that poor utilization of resources takes place.
Shortest Job First(SJF) scheduling algorithm
It is also called the Shortest Job Next (SJN) scheduling. It is both preemptive and non-preemptive. In this scheduling algorithm, the process which has the shortest burst time will be processed first by the CPU. In this, the arrival time of all the processes must be the same. Also, the processor must have to aware about the burst time of all the processes in advance.
It is the non-preemptive mode of scheduling. The preemptive method of SJF scheduling is known as Shortest Remaining Time First scheduling algorithm.
Consider the processes which are given below in the table having arrival time is 0 and burst time is given.
| Process | Burst Time |
| P1 | 10 |
| P2 | 20 |
| P3 | 6 |
| P4 | 4 |
| P5 | 2 |
As we know in this scheduling, the shortest job will be executed by the CPU in the starting. This can be easily understood through GANTT chart which is given below:
![]() Average waiting time= (0+2+6+12+22)/5= 42/5= 8.4 ms
Average waiting time= (0+2+6+12+22)/5= 42/5= 8.4 ms
Advantages of the Shortest Job First Scheduling Algorithm
• It is optimal for minimizing the queuing time.
• It is easy to implement in batch systems as we know in this we know the required CPU time.
• It’s average waiting time, or AWT is minimum amongst all the scheduling algorithms.
Disadvantages of the Shortest Job First Scheduling Algorithm
• it is challenging to implement in the interactive system as we don’t know the required CPU time here.
• Usually, run times are not known in this scheduling.
• If the arrival time of the processes is different, i.e. different processes arrive at different time for the execution, then sometimes, the process which has shortest burst time will have to wait so that the current process can finish its performance. The reason behind this is its non-preemptive mode as in this the current process is not halted in between on arrival of shortest burst process.
This brings the starvation problem which is solved by the process of ageing.
Shortest Remaining Time First (SRTF) scheduling algorithm
It is the preemptive mode of Shortest Job First (SJF) scheduling. In this algorithm, the process which has the short burst time is executed by the CPU. There is no need to have the same arrival time for all the processes. If another process was having the shortest burst time then the current process which is executing get stopped in between the execution, and the new arrival process will be executed first.
Let us understand it with the help of an example:
Consider the processes which are given in the table along with the arrival time and burst time.
| Process | Burst Time | Arrival |
| P1 | 8 | 0 |
| P2 | 4 | 1 |
| P3 | 2 | 2 |
| P4 | 1 | 3 |
| P5 | 3 | 4 |
| P6 | 2 | 5 |
Its GANTT chart is shown below:
• At time 0, only process P1 arrives. So it will be executed .
• The next process P2 arrives at time 1. now the current execution is stopped as P2 has the short burst time. So P1 is preempted after 1 units. Now 7 units of time of process P1 is remaining.
• At time 2, process P3 arrives. The execution of P2 is stopped as the process P3 has short burst time and 3 units of P2 burst time is left.
• At time 3, process P4 arrives. At this point, now the scheduler will check the short burst time among the four processes P1, P2, P3 and P4. P1 and P2 have 7 and 3 unit of burst time left whereas P3 and P4 have 1 unit of burst time left. So, now both have same time, so they will be executed acc to their arrival. Since P3 arrived first, so the process P3 will be executed.
• At time 4, the next process P5 arrives. Now P3 has completed its execution. For now the scheduler will compare the burst time of other processes. The process P4 has least burst time amongst all. So, now process P4 will be executed.
• At time 5, process P6 arrives. Also process P4 has completed its execution,. So now we have 4 processes available P1, P2, P5 and P6. Amongst all P6 has least burst time? So P6 will be executed.
• After that P2, P5 and P1 will be executed acc to SJF.
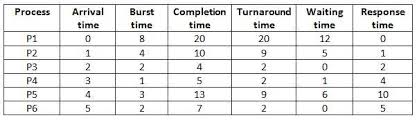
Average waiting time= 24/6=4 ms
Advantages of Shortest Remaining Time First (SRTF) scheduling algorithm
• Generally, it is used in batch system where we have to give preference to the shortest jobs.
• The processes which have the shortest burst time will run fast as compare to the other one.
• In this, we get the increased throughput because a lot of processes gets executed in very small time.
Disadvantages of Shortest Remaining Time First (SRTF) scheduling algorithm
• It is impossible to implement SRTF scheduling algorithm in interactive system as we don’t know the required CPU time here.
• In this, the process which has long burst time will have to wait for long time for their execution because the processes with short burst time are being executed by the CPU.
• Practically, we can’t predict the burst time.
Round Robin scheduling algorithm
Round robin scheduling is the preemptive scheduling algorithm. In this scheduling, every process gets executed cyclically or you can say that a particular time slice is allocated to each process to which we can say as time quantum. Every process, which wants to execute itself, is present in the queue. CPU is assigned to the process for that time quantum. Now, if the process completed its execution in that quantum of time, then the process will get terminated, and if the process does not achieve its implementation, then the process will again be added to the ready queue, and the previous process will wait for its turn to complete its execution.
The round-robin scheduling drives its name from the principle which is known as a round robin. According to this principle, every person will take an equal share of anything which they have with themselves. Round Robin scheduling algorithm is used in a time-sharing system. It is generally used by those operating systems which has multiple clients so that they can make use of resources.
Example of round robin scheduling
In this example, we will take six processes P1, P2, P3, P4, P5 and P6 whose arrival and burst time are given in the table. The time quantum is four units.
| Processes | Arrival Time | Burst Time |
| P1 | 0 | 5 |
| P2 | 1 | 6 |
| P3 | 2 | 3 |
| P4 | 3 | 1 |
| P5 | 4 | 5 |
| P6 | 5 | 4 |
As the structures of ready queue and gantt chart will changes after every scheduling, so we have to maintain it in the algorithm again and again.
Ready Queue
Initially, in the starting, the process P1 will be executed for the given time quantum. So, there will be only one process P1 in the ready queue when we start the scheduling.
| P1 |
| 5 |
Gantt chart
P1 will be executed for 4 units.
Ready Queue
Mid while, during the execution of process P1, some other processes like P2, P3,P4 and P5 arises for the execution in the ready queue. As we know P1 has not completed since its time is 5 and we have 4 units of time slice. So, 1 unit is still left. So it will be again added at the back in ready queue.
| P2 | P3 | P4 | P5 | P1 |
| 6 | 3 | 1 | 5 | 1 |
GANTT chart
Now the gantt chart will be like this.
Ready queue
When the process P2 is executing, another process P6 arrives in the ready queue. As we know that the process P2 has not terminated its execution as its 2 units of burst time is still left. So, for now we will add the process P2 in the ready queue at the back so that it can complete its execution.
| P3 | P4 | P5 | P1 | P6 | P2 |
| 3 | 1 | 5 | 1 | 4 | 2 |
GANTT CHART
Now, P3 will be executed for 3 units of time slice as its bursts time is 3 units.
Ready queue
Now the process P3 is completed in the time slice of 4 units. So, we will not add P3 in the ready queue and now we will execute the next process P4.
| P4 | P5 | P6 | P1 | P2 |
| 1 | 5 | 1 | 4 | 2 |
GANTT CHART
Ready queue
The next process which is in the ready queue is P5 and it has 5 units of bursts time. Also, the process P4 gets completed or you can say that has terminated its execution as it has only 1 unit of bursts time.
| P5 | P6 | P1 | P2 |
| 5 | 1 | 4 | 2 |
GANTT chart
Ready Queue
Now the process P5 has not completed its execution as 1 unit of burst time is left. So we add it in the ready queue in the back so that it can be further executed by the CPU.
| P1 | P6 | P2 | P5 |
| 1 | 4 | 2 | 1 |
GANTT chart
Now the turn of the process P1 has come according to the ready queue. So, for now the process P1 will complete its execution. As we know it requires only 1 unit of bursts time, so it will get completed in this chance of execution.
Ready queue
As the process P1 also get completed. So, we will not add it into the ready queue. Now, overall only three processes P6, P2 and P5 are left.
| P6 | P2 | P5 |
| 4 | 2 | 1 |
GANTT CHART
Now P6 has 4 units of bursts time. So it will get executed in 4 units of time slice
Ready queue
Since the process P6 is executed completely. So, we will not add it to the ready queue. Now only 2 processes left in the ready queue which are P2 and P5.
| P2 | P5 |
| 2 | 1 |
GANTT CHART
Now P2 will be executed again and it requires only 2 units of bursts time. So now it will be completed.
Ready queue
Only process left in the ready queue is P5 which requires only 1 unit of bursts time. As we know our time slice is of 4 units. So it will get completed in the next burst.
| P5 |
| 1 |
GANTT CHART
The process P5 will get executed until it get completed as it is the only process left in the ready queue.
Now we will calculate turn around time, completion time and average waiting time which is shown in the below table.
Turn around time= completion time- arrival time
Waiting time= turn around time – burst time
Average waiting time= (12+16+6+8+15+11)/6= 76/6 = 12.66 units
Advantages of round robin scheduling
• It is simple.
• It is easy to implement.
• It deals with all process without any priority as no priority is given in this type of scheduling.
• In this, all jobs get easily allocated to the CPU for their execution.
• Here, no convoy effect or starvation occurs as it occurs in first come first serve scheduling algorithm.
• Round robin scheduling algorithm does not depend upon burst time. So we can easily implement the round robin scheduling algorithm on the system.
Disadvantages of round robin scheduling
• As we know that the time quantum is the main requirement of the round robin scheduling algorithm to execute processes. So, deciding a perfect time quantum for scheduling the processes is a very difficult and not an optimal task.
• Higher the time quantum, higher the response time of the system.
• Lower the time quantum, higher the context switching overhead.
Priority based scheduling algorithm
This is the scheduling algorithm which is based on the priority of the processes. In priority scheduling, the scheduler itself chooses the priority of the task, and then they will be executed according to their preference which is assigned to them by the scheduler. The process which has the highest priority will be firstly processed by the CPU, and the process which has the lowest priority will be executed by the CPU when the current process terminates its execution.
Example: Shortest Job First(SJF) scheduling.
| Process | Burst Time | Priority |
| P1 | 7 | 2 |
| P2 | 10 | 5 |
| P3 | 4 | 1 |
| P4 | 2 | 4 |
| P5 | 6 | 3 |
Now we know that the processes are executed on the basis of their priority which is assigned to them.
The process P3 has the highest priority. So, it will be executed by the CPU firstly. 2nd priority is given to the process P1. So after process P3, the process P1 will complete its execution and so on the process P5, P4 and P2 will be executed. Their execution can be shown through the GANTT chart which is given below:
The average waiting time or AWT= (0+4+11+17+19)/5= 51/5= 10.2 ms
On the Basis of Execution
Priorities are of two types: static and dynamic.
Static priorities are those priorities which we defined while creating the list of processes or you can say that the number of priority does not changes when the process of execution is going on.
Dynamic priorities are those which we defined on the basis of the behavior of the processes or you can say that the priority keeps changing itself when the process of execution is going on as per its own needs.
On the basis of definition
Priorities are further of two types: externally defined and internally defined.
Internally defined priorities are those which make use of any measurable unit so that they can calculate the priority of a process.
Example: time limits, file requirements includes number of open files etc.. and memory requirements etc.
Externally defined priorities are those which make use of some criteria which is beyond our operating system. It includes the sum of resources which are being utilized for computer use, significance of process, user preference and some other factors.
Example: the department which is sponsoring our work, politics, the amount of fund which is being paid for computer use and the type of fund which is being paid for computer use, process importance etc..
On the basis of preemption
It is of two types: preemptive and non-preemptive.
Preemptive priority scheduling algorithm is that which preempts the CPU while executing the process in case high priority process appears in front of the CPU.
Non-preemptive priority scheduling algorithm is that which does not preempts the CPU. It simply puts the new process at the top of the ready queue.
Advantages of Priority Scheduling
• The priority of process is selected on the basis of memory requirement, user preference or the requirement of time.
• Processes are executed on the basis of priority. So high priority does not need to wait for long which saves time.
• It is easy to use.
• It is a user friendly algorithm.
• Simple to understand.
• it has reasonable support for priority.
Disadvantages of Priority Scheduling
• The major disadvantage of priority scheduling is the process of indefinite blocking or starvation. This problem appears when a process is ready to be executed but it has to wait for the long time for execution by CPU because other high priority processes are executed by the CPU.
The problem of starvation can be solved by aging. Aging is a technique in which the system gradually increases the priority of those processes which are waiting in the system from a long time for their execution.
• In case if we have the processes which have the same priority, then we have to make use of 2nd scheduling algorithm.
• If the system get crashes eventually, then all the processes having low priority which are not finished yet, also get lost.
Highest Response Ratio Next (HRRN) scheduling algorithm
It is a non-preemptive scheduling algorithm which is done on the basis of a new parameter called Response Ratio (RR). We will calculate the response ratio of all the processes and the process which has the highest response ratio will be implemented first.
Response Ratio is given by
Response Ratio= (Waiting time+ Burst time)/ Burst time
Example
List of processes with arrival time and burst time is given in the table.
| Process | Arrival Time | Burst Time |
| P0 | 0 | 3 |
| P1 | 2 | 5 |
| P2 | 4 | 4 |
| P3 | 6 | 1 |
| P4 | 8 | 2 |
Firstly the process P0 arrives. So it will be executed.
P0 executed for 3 units. After this, process P1 arrives at time 3 which will be executed.
After the execution of P1, all the processes get available. So now for deciding we have to calculate the response ratio of all the remaining processes.
RR(P2) = ((8-4)+4 )/4 = 2
RR(P3) = (2+1)/1= 3
RR(P4) = (0+2)/2= 1
Since P3 has highest response ratio. So it will be executed first.
P0 executed for 3 units. After this, process P1 arrives at time 3 which will be executed.
Now the remaining processes are P2 and P4. So now we will again calculate the response ratio.
RR(P2) = (5+4)/4 = 2.25
RR(P4) = (1+2)/2 = 1.5
Here, RR of P2 is higher. So now we will execute P2.
Only process P4 is left for the CPU to execute. So now P4 will be executed.
Average waiting time= 13/5= 2.6 msws
Advantages of HRRN scheduling
• The performance of HRRN scheduling is better than SJF scheduling algorithm.
• It favors the shortest jobs.
Disadvantages of HRRN scheduling
• We can not implement it practically.
The multilevel Queue scheduling algorithm
In this algorithm, the ready queue is divided into seven separate lines. The process is divided into different queues which are based upon the priority of the process like memory size, process type, etc.…
The various queues have their scheduling algorithm, and these algorithms can be the same or different.
Example
We will take three different types of processes which have their priority and scheduling algorithms as given below in the diagram:
• Here, the system process has the highest priority which has its processes to run.
• In an interactive process, there can be any interaction like listening to music, playing the game, etc.
• In a batch process, we submit the jobs to the processor.
Advantages of Multilevel Queue scheduling algorithm
• We can apply different scheduling algorithms to different processes.
• It has low scheduling overhead.
• There are many processes which we are not able to put them in the one single queue which is solved by this scheduling as we can now put them in different queues.
Disadvantages of Multilevel Queue scheduling algorithm
• Its main drawback is the starvation problem which exists for the lowest level of processes which means the most inferior priority process has to wait for a long time as high priority process takes much time to execute.
• The process doesn’t move from one queue to another queue.
• It is inflexible.
Multilevel Feedback Queue Scheduling algorithm
This scheduling algorithm allows the processes to move from one queue to another. Suppose if there a process which uses too much of CPU time, then we can move that process to the lower priority queue so that we can execute it later on. Similarly, if there is a process which is waiting for too long in a lower priority queue, we can move it to the high priority queue so that it can be executed. Multilevel feedback queue scheduling algorithm also prevents starvation from occurring.
Advantages of Multilevel Queue scheduling algorithm
• It prevents starvation.
• It speeds up the flow of task execution.
• It improves the overall performance of the system.
 Dinesh Thakur holds an B.C.A, MCDBA, MCSD certifications. Dinesh authors the hugely popular
Dinesh Thakur holds an B.C.A, MCDBA, MCSD certifications. Dinesh authors the hugely popular