Normalization is the process of removing redundant data from your tables in order to improve storage efficiency, data integrity and scalability. This improvement is balanced against an increase in complexity and potential performance losses from the joining of the normalized tables at query-time. There are two goals of the normalization process: eliminating redundant data (for example, storing the same data in more than one table) and ensuring data dependencies make sense (only storing related data in a table). Both of these are worthy goals as they reduce the amount of space a database consumes and ensure that data is logically stored.
We’ll be covering the following topics in this tutorial:
Why We Need Normalization?
Normalization is the aim of well design Relational Database Management System (RDBMS). It is step by step set of rules by which data is put in its simplest forms. We normalize the relational database management system because of the following reasons:
• Minimize data redundancy i.e. no unnecessarily duplication of data.
• To make database structure flexible i.e. it should be possible to add new data values and rows without reorganizing the database structure.
• Data should be consistent throughout the database i.e. it should not suffer from following anomalies.
• Insert Anomaly – Due to lack of data i.e., all the data available for insertion such that null values in keys should be avoided. This kind of anomaly can seriously damage a database
• Update Anomaly – It is due to data redundancy i.e. multiple occurrences of same values in a column. This can lead to inefficiency.
• Deletion Anomaly – It leads to loss of data for rows that are not stored else where. It could result in loss of vital data.
• Complex queries required by the user should be easy to handle.
On decomposition of a relation into smaller relations with fewer attributes on normalization the resulting relations whenever joined must result in the same relation without any extra rows. The join operations can be performed in any order. This is known as Lossless Join decomposition.
The resulting relations (tables) obtained on normalization should possess the properties such as each row must be identified by a unique key, no repeating groups, homogeneous columns, each column is assigned a unique name etc.
Advantages of Normalization
The following are the advantages of the normalization.
• More efficient data structure.
• Avoid redundant fields or columns.
• More flexible data structure i.e. we should be able to add new rows and data values easily
• Better understanding of data.
• Ensures that distinct tables exist when necessary.
• Easier to maintain data structure i.e. it is easy to perform operations and complex queries can be easily handled.
• Minimizes data duplication.
• Close modeling of real world entities, processes and their relationships.
Disadvantages of Normalization
The following are disadvantages of normalization.
• You cannot start building the database before you know what the user needs.
• On Normalizing the relations to higher normal forms i.e. 4NF, 5NF the performance degrades.
• It is very time consuming and difficult process in normalizing relations of higher degree.
• Careless decomposition may leads to bad design of database which may leads to serious problems.
How many normal forms are there?
They are
• First Normal Form
• Second Normal Form
• Third Normal Form
• Boyce-Codd Normal Form
• Fourth Normal Form
• Fifth Normal Form
• Sixth or Domain-key Normal form
What do we mean when we say a table is not in normalized form?
Let’s take an example to understand this,Say I want to create a database which stores my friends name and their top three favorite artists. This database would be quite a simple so initially I’ll be having only one table in it say friends table. Here FID is the primary key.

This table is not in normal form why?
Favorite Artist column is not atomic or doesn’t have scalar value i.e. it has having more that one value.
Let’s modify this table

This table is also not in normal form why?
We have now changed our table and now each column has only one value!! (So what’s left?)
Because here we are having multiple columns with same kind of value.
I.e. repeating group of data or repeating columns.
So what we need to do to make it normal or at least bring it in First Normal Form?
- We’ll first break our single table into two.
- Each table should have information about only one entity so it would be nice if we store our friend’s information in one table and his favorite artists’ information in another
(For simplicity we are working with few columns but in real world scenario there could be column like friend’s phone no, email , address and favorites artists albums, awards received by them, country etc. So in that case having two different tables would make complete sense)
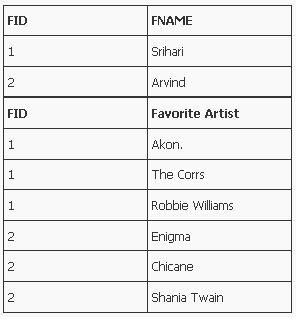
FID foreign key in FavoriteArtist table which refers to FID in our Friends Table.
Now we can say that our table is in first normal form.
Remember For First Normal Form
Column values should be atomic, scalar or should be holding single value
No repetition of information or values in multiple columns.
So what does Second Normal Form means?
For second normal form our database should already be in first normal form and every non-key column must depend on entire primary key.
Here we can say that our Friend database was already in second normal form l.
Why?
Because we don’t have composite primary key in our friends and favorite artists table.
Composite primary keys are- primary keys made up of more than one column. But there is no such thing in our database.
But still let’s try to understand second normal form with another example
This is our new table
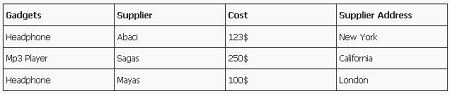
In about table ITEM+SUPPLIER together form a composite primary key.
Let’s check for dependency
If I know gadget can I know the cost?
No same gadget is provided my different supplier at different rate.
If I know supplier can I know about the cost?
No because same supplier can provide me with different gadgets.
If I know both gadget and supplier can I know cost?
Yes than we can.
So cost is fully dependent (functionally dependent) on our composite primary key (Gadgets+Supplier)
Let’s start with another non-key column Supplier Address.
If I know gadget will I come to know about supplier address?
Obviously no.
If I know who the supplier is can I have it address?
Yes.
So here supplier is not completely dependent on (partial dependent) on our composite primary key (Gadgets+Supplier).
This table is surely not in Second Normal Form.
So what do we need to do to bring it in second normal form?
Here again we’ll break the table in two.
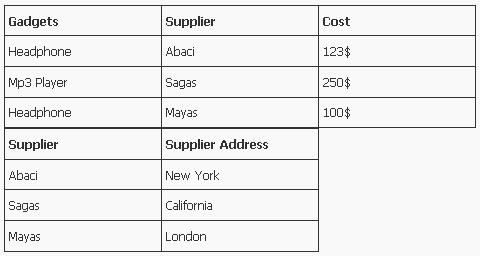
We now how to normalize till second normal form.
But let’s take a break over here and learn some definitions and terms.
Composite Key: -Composite key is a primary key composed of multiple columns.
Functional Dependency – When value of one column is dependent on another column.
So that if value of one column changes the value of other column changes as well.
e.g. Supplier Address is functionally dependent on supplier name. If supplier’s name is changed in a record we need to change the supplier address as well.
S.Supplier–as.SupplierAddress
“In our s table supplier address column is functionally dependent on the supplier column”
Partial Functional Dependency – A non-key column is dependent on some, but not all the columns in a composite primary key.
In our above example Supplier Address was partially dependent on our composite key columns (Gadgets+Supplier).
Transitive Dependency– A transitive dependency is a type of functional dependency in which the value in a non-key column is determined by the value in another non-key column.
With these definitions in mind let’s move to Third Normal Form.
For a table in third normal form
• It should already be in Second Normal Form.
• There should be no transitive dependency, i.e. we shouldn’t have any non-key column depending on any other non-key column.
Again we need to make sure that the non-key columns depend upon the primary key and not on any other non-key column.
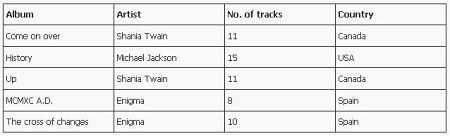
Although the above table looks fine but still there is something in it because of which we will normalize it further.
Album is the primary key of the above table.
Artist and No. of tracks are functionally dependent on the Album(primary key).
But can we say the same of Country as well?
In the above table Country value is getting repeated because of artist.
So in our above table Country column is depended on Artist column which is a non-key column.
So we will move that information in another table and could save table from redundancy i.e. repeating values of Country column.
 Dinesh Thakur holds an B.C.A, MCDBA, MCSD certifications. Dinesh authors the hugely popular
Dinesh Thakur holds an B.C.A, MCDBA, MCSD certifications. Dinesh authors the hugely popular