“A logically interrelated collection of shared data (and a description of this data) physically distributed over a computer network.”
We’ll be covering the following topics in this tutorial:
Distributed DBMS
The software system that permits the management of the distributed database and makes the distribution transparent to users.
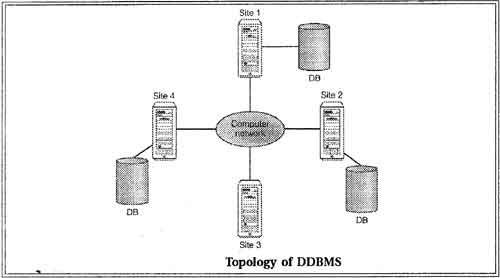
A Distributed Database Management System (DDBMS) consists of a single logical database that is split into a number of fragments. Each fragment is stored on one or more computers under the control of a separate DBMS, with the computers connected by a communications network. Each site is capable of independently processing user requests that require access to local data (that is, each site has some degree of local autonomy) and is also capable of processing data stored on other computers in the network.
Users access the distributed database via applications. Applications are classified as those that do not require data from other sites (local Applications) and those that do require data from other sites (global applications). We require a DDBMS to have at least one global application.
Characteristics of Distributed Database Management System
A DDBMS has the following characteristics:
 A collection of logically related shared data;
A collection of logically related shared data;
- The data is split into a number of fragments;
- Fragments may be replicated;
- Fragments/replicas are allocated to sites;
- The sites are linked by a communications network;
- The data at each site is under the control of a DBMS;
- The DBMS at each site can handle local applications, autonomously;
- Each DBMS participates in at least one global application
It is not necessary for every site in the system to have its own local database, as illustrated by the topology of the DDBMS shown in figure.
Banking Example
Using distributed database technology, a bank may implement their database system on a number of separate computer systems rather than a single, centralized mainframe. The computer systems may be located at each local branch office: for example, Amritsar, Jalandhar, and Qadian. A network linking the computer will enable the branches to communicate with each other, and DDBMS will enable them to access data stored at another branch office. Thus a client living in Amritsar can also check his/her account during the stay in Jalandhar or Qadian.
From the defination of the DDBMS, the system is expected to make the distribution transparent (invisible) to the user. Thus, the fact that a distributed database is split into fragments that can be stored on different computers and perhaps replicated should be hidden from the user. The objective of transparency is to make the distributed system appear like a centralized system. This is sometimes referred to as the fundamental principle of distributed DBMSs. This requirement provides significant functionality for the end-user but, unfortunately, creates many additional problems that have to be handled by the DDBMS.
Distributed Processing
It is important to make a distinction between a distributed DBMS and distributed processing.
Distributed Processing is a centralized database that can be accessed over a computer network. .
The key point with the definition of a distributed DBMS is that the system consists of data that is physically distributed across a number of sites in the network. The data is centralized, even though other users may be accessing the data over the network, we do not consider this to be a distributed DBMS, simply distributed processing. We illustrate the topology of distributed processing in figure. Compare this figure, which has a central database at site 2, with figure which shown several sites each with their own database (DB).

Parallel DBMSs
Parallel DBMS is a DBMS running across multiple processor and disks that is designed to execute operations in parallel, whenever possible, in order to improve performance. Parallel DBMSs are again based on the idea that single process of systems can no longer meet the growing requirements for cost-effective scalability, reliability, and performance. A powerful and financially attractive alternative to single processor-driven DBMS is a parallel DBMS driven by multiple processors. Parallel DBMSs link multiple, smaller machines to achieve the same throughput as a single, larger machine, often with greater scalability and reliability than single-processor DBMSs.
To provide multiple processors with common access to a single database, a parallel DBMS must provide for shared resource management. Which resources are shared, and how those shared resources are implemented, directly affects the performance and scalability of the system, which, in turn, determines its appropriateness for a given application environment.

The three main architectures for parallel DBMS, as illustrated in figure are:
• Shared Memory
• Shared Disk
• Shared Nothing
Shared Memory: Shared memory is a tightly coupled architecture in which multiple processors within a single system share system memory as shown in figure. Known as symmetric multiprocessing (SMP), this approach has become popular on platforms ranging from personal workstations that support a few microprocessors in parallel, to large RISC (Reduced Instruction Set Computer) based machines, all the way up to the largest mainframes. This architecture provides high-speed data access for a limited number of processors, but it is not scalable beyond about 64 processors when the interconnection network becomes a bottleneck.
Shared Disk: Shared Disk is a loosely coupled architecture optimized for application that are inherently centralized and require high availability and performance. Each processor can access all disks directly, but each has its own private memory as shown in figure. Shared disk systems are sometimes referred to as a cluster.
Shared Nothing: Shared nothing, often known as Massively Parallel Processing (MPP), is a multiple processor architecture in which each processor is part of a complete system, with its own memory and disk storage as shown in fig. The database is partitioned among all the disks on each system associated with the database, and data is transparently available to users on all systems. This architecture is more scalable than shared memory and can easily support a large number of processors. However, performance is optional only when requested data is stored locally.
While the shared nothing definition sometimes includes distributed DBMSs, the distribution of data in a parallel DBMS is based solely on performance considerations. Further, the nodes of a DDBMS are typically geographically distributed, separately administered, and have a slower interconnection network, whereas the nodes of a parallel DBMS are typically within the same computer or within the same site.
Parallel technology is typically used for very large database possibly of the order of terabytes (1012 bytes) or systems that have to process thousands of transactions per second. These systems need access to large volumes of data and must provide timely responses to queries. A parallel DBMS can use the underlying architecture to improve the performance of complex query execution using parallel scan, join and sort techniques that allow multiple processor nodes automatically to share the processing workload.
 Dinesh Thakur holds an B.C.A, MCDBA, MCSD certifications. Dinesh authors the hugely popular
Dinesh Thakur holds an B.C.A, MCDBA, MCSD certifications. Dinesh authors the hugely popular