In a mesh network, the routing of packets is part of a complex algorithm, by the distribution of decisions, which are both space and time. A node should know the status of all the other nodes before deciding where to send a packet, which is impossible to achieve.
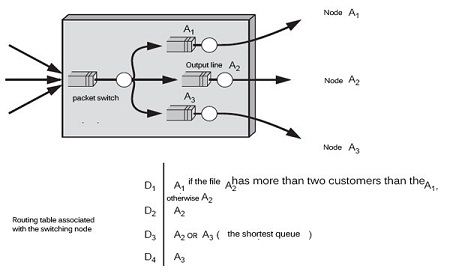
First, let’s look at the components necessary for the establishment of a routing. It should firstly be a routing table, which is as illustrated in figure.

It can be seen that a transfer node is formed of output lines, which emit frames obtained from packets. The packets are routed by the node to an output line through the routing table. If a packet arrives at node with for destination final, D1 node, the node can send this packet to the output line A1 or to the output line A2. The decision is made on local criteria in the present case. By example, it sends the packet on the shortest queue. If the final destination is D2, the package is set in the A2 line.
We’ll be covering the following topics in this tutorial:
Centralized Routing
Centralized routing is characterized by the existence of a center, which takes decisions on the definition of a new table and sending the table to all transfer network nodes. This central node receives information from all network components, and designs its routing table following specific algorithms in advance.
Key considerations to be taken into account to determine the best routes in a network, whether in routing or to the opening of a road, are following:
• cost of the bonds;
• cost of switching in a knot;
• requested rate;
• Transit delay requested;
• Number of nodes to traverse;
• Safe transport of certain classes of packets;
• Occupation of the memories of the switching nodes;
• Occupation of the line couplers.
Routing algorithms using mostly cost criteria. We find, for example, the lowest cost algorithm, which, as its name suggests, is to find the path that minimizes the higher the price. The simplest algorithms, and almost always the most efficient, give a cost of 1 each time through a node. This is the algorithm of the shortest route. Contrary to what could be thinking is often a good way to proceed. One can easily add bias to reflect the occupancy of the buffers, the use of output lines, etc.
The fixed routing is another particularly simple technique since the table does not vary in time. Each time a packet enters a node, it is sent in the same direction which corresponds, in almost all cases, the algorithm to the shortest route. However, one can not speak of routing algorithm in this case, since the routing is fixed and does not require update. The fixed route goes along with a control center, which manages the serious breakdowns and generates a new table when a node fails or a communication line is broken. We call this fixed routing between updates day.
Can be improved by taking into account fixed routing of events indicated by the network, such congestion or occupations lines or excessive memory. Every ten seconds, all network nodes send a control packet indicating their situation. From these reports, the central node is developing a new routing table, which is broadcast.
Sending routing tables asynchronously is a more sophisticated technique. The central node broadcasts to all nodes a new routing table as soon as this table has changed sufficiently over that in force. In other words, the control center stands the routing tables as and with the arrival of new and sends information to all nodes the first routing table that seems to him sufficiently different from the previous. Adaptation is here and not asynchronous synchronous as before.
The performance of this centralized routing is architecture and topology network. Indeed, the main problem of routing and adaptation is that they must take place in real time. Between the times a node sends a report involving a new routing and when the new routing table arrives, it should not be have substantial change in the system state. This condition is badly made if the network is large and overcrowded roads, control packets being little priority than packets carrying information.
Routing the quality corresponds to a first view to adaptation increasingly sophisticated. This is where there is the second major problem regarding the performance, also related to the first: the sophistication leads to network overload by control packets, which can prevent a real-time operation.
It can be seen that a given routing algorithm does not have the same efficiency for a network three nodes, for example, that for a network to twenty knots. The first conclusion we can draw is that it is no better algorithm than another, even for a well-defined network, since it depends on the traffic. Moreover, it appears that there is an optimum in the complexity of the adaptive algorithm for not overloading the network unnecessarily.
Distributed Routing
The simplest distributed routing techniques, flood, is not adaptive. When a packet is received in a node, it is forwarded to all destinations possible. This efficient routing is nevertheless penalizing in terms of flow and can not be adopted in specific cases, such as networks where real time is essential and low traffic.
In a little more complex algorithm, adaptability begins to appear. It concerns only a dimension, time. For a package in transit node i and leader to node j, a plurality of output lines can be selected. In the method Routing called hot potatoe, we try to get rid of as quickly package possible by transmitting the first empty line output. In fact, it only uses Never a hot potatoe pure method. Preferred more elaborate techniques in coefficients which are assigned to different output lines for a destination given.
There is almost always a more appropriate output line than others. All these techniques are local, since the states of other nodes are not taken into account. To adapt the algorithm in space, it is first necessary to have an idea what is happening in neighboring nodes. Without the use of control packets, there is obtained sample traffic from neighboring nodes by counting arrivals from these nodes. These can also send synchronously or asynchronously an account of their condition. Taking into account these implicit information or explicit, it is possible to choose the output queue knowingly. Adaptation Space is still limited, since a fracture, two links below, may not be taken into account by the minutes of the neighboring nodes. A more technical fine is defined in the next section, enabling a node to determine its table routing function of all system conditions.
The distributed routing algorithm, which must fully adapt to the times space and time, requires a complete knowledge of the status of all network nodes. The various nodes must exchange messages. If each node transmits a message to all the others, total traffic so may increase worrying. To stay within reasonable limits, a node transmits an account made to its neighbors. These must be considered in their own account. Again, update the instants can be synchronous or asynchronous. The advantages and disadvantages of these two types of measurement are the same as in the centralized case.
 Dinesh Thakur holds an B.C.A, MCDBA, MCSD certifications. Dinesh authors the hugely popular
Dinesh Thakur holds an B.C.A, MCDBA, MCSD certifications. Dinesh authors the hugely popular